Ampy: A Python AM implementation
Paul Huff
Linguistics 615
Motivation
- Implementing the algorithm for myself gives me a clearer understanding of how it works.
- Python is a clean, object oriented language which allows for some interesting re-tooling of the basic algorithm.
- Programming is fun!
Context
- Statistical classifiers in general try and decide, based on a set of examples, how a new item best fits in the mix.
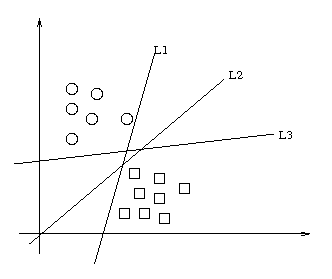
- AM does this in a rather novel way (e.g. compare k-NN).
Design principles
- Build a clean, easy to understand implementation.
- Use a good object model so that overloading and manipulation are easy.
- Make it hackable.
The basic algorithm
- Snarf the examples, putting each one in several big containers.
- For each test set member:
- Find the analogical set (the list of containers we need to look in).
- Tally up the votes.
- Announce the winner
Considerations
- This is the stupid version of AM (where stupid = slow).
- However, it allows for improvements to the process.
- Weighted Analogical Modeling (WAM) (explain on board)
- Map-Reduce: perhaps easier with this approach?
- Abstract Analogical Modeling, Weighted Abstract Analogical Modeling (future direction)
- Can get rid of the niggling bits (command line options, gui, etc.).
- Open source project, ampy.sf.net (this presentation), sf.net/projects/ampy for downloads, etc.